
Nvidia's data center chips, the ones training and serving today's AI models, now make up roughly 88% of its revenue. It holds over 90% share of the AI training chip market. None of that exists if one chip most people have never heard of hadn't worked, on the first try, in 1997, when the company had about a month of payroll left.
I still have that chip. An ASUS AGP-V3000, built on the Nvidia RIVA 128. Four EtronTech memory chips, 4MB of SGRAM, a passive heatsink, a single VGA port. It never trained anything. It never ran a model. It rendered triangles for late-90s PC games, and it's the reason there's still a company called Nvidia to build the chips that do the training now.
The Bet Nobody Remembers
Everyone knows Nvidia as the company behind the AI boom. Fewer people know it almost didn't survive long enough to get there.
In the mid-90s, Nvidia bet its future on the NV1, a chip built around quadratic surfaces instead of the triangle-based rendering Microsoft's DirectX was standardizing on. The bet was wrong. Diamond Multimedia had ordered 250,000 units. Roughly 249,000 came back. Nvidia shrank to about 40 people.
Sega had contracted Nvidia to build the graphics chip for the Dreamcast, the NV2. After more than a year of work, Jensen Huang told Sega it wouldn't meet their requirements, and asked to be released from the contract, then asked Sega to pay the final milestone anyway. Sega America's CEO, Shoichiro Irimajiri, agreed to a payment reported at around $5 million. Nvidia had roughly one month of payroll left when it landed, close enough to the edge that the company's unofficial motto at the time, by its own account, was "our company is thirty days from going out of business."
That payment didn't fix anything. It bought one more shot. It had to work.
One Chip, Seven Months, No Safety Net
The chip that came out of that shot was the RIVA 128. Standard development at the time ran one to two years, with physical prototype runs to catch design flaws before committing to production. Nvidia didn't have that runway.
It compressed the cycle to roughly seven months by validating the entire design in simulation and committing to the production run without ever holding a physical chip. If the simulation had missed something, there was no money left to recover from it.
It wasn't flawless. Of the 32 blend modes DirectX supported at the time, the RIVA 128 only handled 8. Nvidia had to convince developers to build within that constraint rather than wait for full compliance. The bet worked because the core architecture, triangles, was right, not because the execution was clean.
The RIVA 128 sold over a million units in its first four months. That's not a footnote in gaming hardware history, it's the reason Nvidia was still solvent two years later to keep iterating, generation after generation, toward the architecture line that eventually became CUDA, and eventually became the hardware training GPT-scale models.
History usually credits the GeForce 256, which shipped two years later, with saving the company. It didn't need saving by then, this chip had already done that. GeForce made Nvidia dominant. This one made sure there was a company left to dominate anything with. Nobody outside a hardware forum needs to care about that distinction. What's worth caring about is what it says: the move that keeps a company alive and the move that makes it famous are rarely the same decision, and the one that keeps you alive usually gets forgotten first.
Why I Kept It
I'm not a collector. I don't have a shelf of retro hardware. I kept this card because I bought it when 3D acceleration in a home PC was still a novelty, when nobody was mining anything with a GPU, and when "AI chip" wasn't a phrase that existed. It was just a card that made games look better.
Holding it next to what Nvidia is now, a company whose chips train the models the entire industry runs on, is a strange feeling. Not because the jump is impressive, though it is. Because the jump wasn't inevitable. It happened because a company on the edge of shutting down made one correct bet on the one variable that mattered, shipped it under pressure with no room to recover from a miss, and turned out to be right.
What 4MB Became
The RIVA 128 ran 3.5 million transistors on a 350nm process, clocked at 100MHz, moving data through 4MB of SGRAM at 1.6GB/s. That was the entire chip.
The workstation-class card a good chunk of today's AI infrastructure work eventually depends on somewhere in the stack is the RTX PRO 6000 Blackwell: 92.2 billion transistors, 24,064 CUDA cores, 96GB of GDDR7, 1,792GB/s of memory bandwidth, 600W under load.
| RIVA 128 (1997) | RTX PRO 6000 Blackwell (2026) | |
|---|---|---|
| Transistors | 3.5 million | 92.2 billion (~26,000x) |
| Memory | 4MB SGRAM | 96GB GDDR7 (~24,000x) |
| Memory bandwidth | 1.6 GB/s | 1,792 GB/s (~1,120x) |
| Process node | 350nm | ~4nm-class |
| Power draw | Passive, no fan | 600W |
| Launch price | ~$200 (~$415 in 2026 dollars) | ~$8,500 |
| Job | Render triangles for games | Train and serve production AI models |
Launch price adjusted for inflation using US CPI, 1997 to 2026 (~107% cumulative). Even correcting for that, the RTX PRO 6000 costs roughly 20x what the RIVA 128 did in real terms, for a card built for a completely different job.
Transistor count is the cleanest single line to draw across all nine generations in between, it's the one spec that's been measured the same way since 1997:
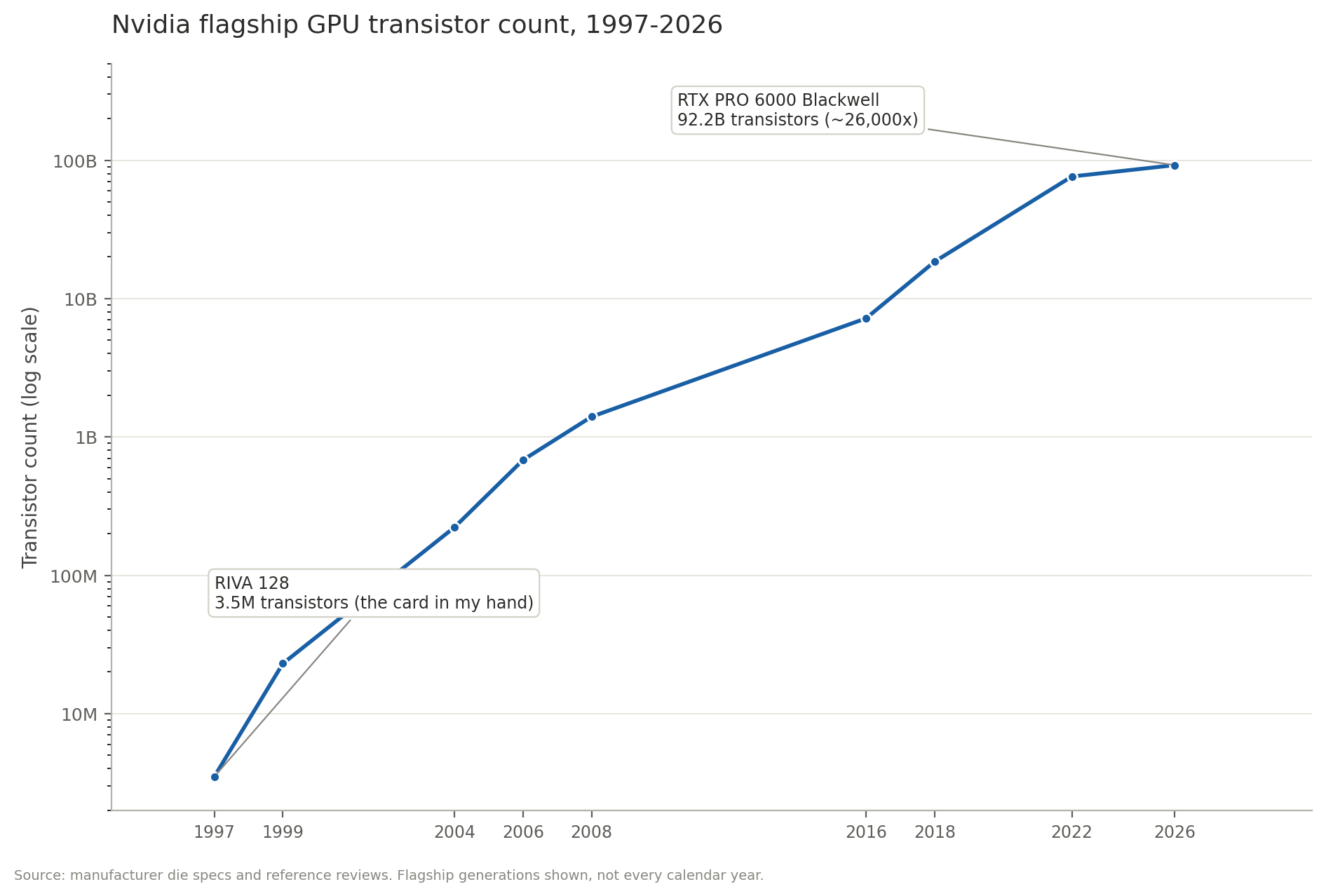
Flagship-generation transistor counts, not every calendar year, Nvidia doesn't ship a new architecture annually.
Nvidia didn't jump from 1997 to Blackwell in one step. It compounded, one funded generation at a time. Data center chips, the direct descendants of that lineage, now generate roughly 88% of Nvidia's revenue and cover over 90% of the AI training chip market. None of that compounding, and none of that revenue, happens if the chip in my hand doesn't work on the first try.
The Rule
Most companies that skip validation under financial pressure don't get a comeback story. They get a second failure. The lesson isn't "take the big risk." It's narrower: when the safe option doesn't exist, the quality of the call comes down to how well you understood the one thing that actually mattered, and whether you can tell the difference between being certain and just hoping.
I think about that constantly in my own work shipping production AI systems. Neither carries Nvidia's 1996 stakes. But the shape repeats: ship the best version of a system you can build, with the information you have, under a deadline that won't move, and find out in production whether you read the constraint correctly.
Nvidia was right. Most companies in that position aren't. Worth remembering next time someone describes their AI infrastructure bet as obvious in hindsight. It rarely was at the time.
The card still works, as far as I know. I haven't plugged it in. Some things are better left as proof than as demo.
About the Author
Netanel Eliav builds production AI systems — agentic workflows, RAG pipelines, LLM infrastructure, and evaluation frameworks. London-based, global AI leader.
LinkedIn · GitHub · inetanel.com
Related Resources - NVIDIA Corporate Timeline — Nvidia's own record of the RIVA 128 launch and the "thirty days from going out of business" period