
Introduction
GPT-5.4 launched on March 5, 2026. Every headline called it a Claude killer. Most of them were wrong — but not for the reason you think.
The real picture is messier and more useful. Both models have genuine strengths, real failure modes, and different cost structures that matter at production throughput. Most comparisons I've seen got the pricing wrong (using old Opus numbers), made invalid SWE-Bench comparisons across different variants, and missed the GPT-5.4 long-context pricing cliff entirely.
This is the version that gets it right. Benchmark data from the official release reports, pricing cross-referenced against Portkey's independent analysis, and failure modes from building production agentic systems — not from reading the launch post.
What a technical lead gets from this: a specific routing decision for every major coding task type, the accurate cost math at production throughput, and the two failure modes of each model that will actually hit you in production.
Model Specifications
| Specification | Claude Opus 4.6 | GPT-5.4 |
|---|---|---|
| Release date | Feb 5, 2026 | March 5, 2026 |
| Context window | 1M tokens (beta) | 1.05M tokens |
| Max output tokens | 128K | 128K |
| API input pricing | $5.00 / M tokens | $2.50 / M tokens |
| API output pricing | $25.00 / M tokens | $15.00 / M tokens |
| Cached input pricing | $2.50 / M tokens | $1.25 / M tokens |
| Long context surcharge | None — flat pricing | 2× input past 272K tokens ($5.00/M) |
| Native computer use | Yes | Yes — built-in, no wrappers |
| Multi-agent orchestration | Agent Teams (native) | None native — build your own |
Note on pricing: earlier comparisons circulated $15/$75 for Opus — that's incorrect. Current pricing is $5/$25. The practical cost gap is ~2×, not 6×.
Benchmark Scorecard
Both companies reported on different benchmark variants — a critical nuance most comparisons ignore. Where the methodology is confirmed identical (via matching GPT-5.2 Pro baseline scores across both vendors), I call it a direct comparison. Where they reported different variants (SWE-Bench), I flag it explicitly.
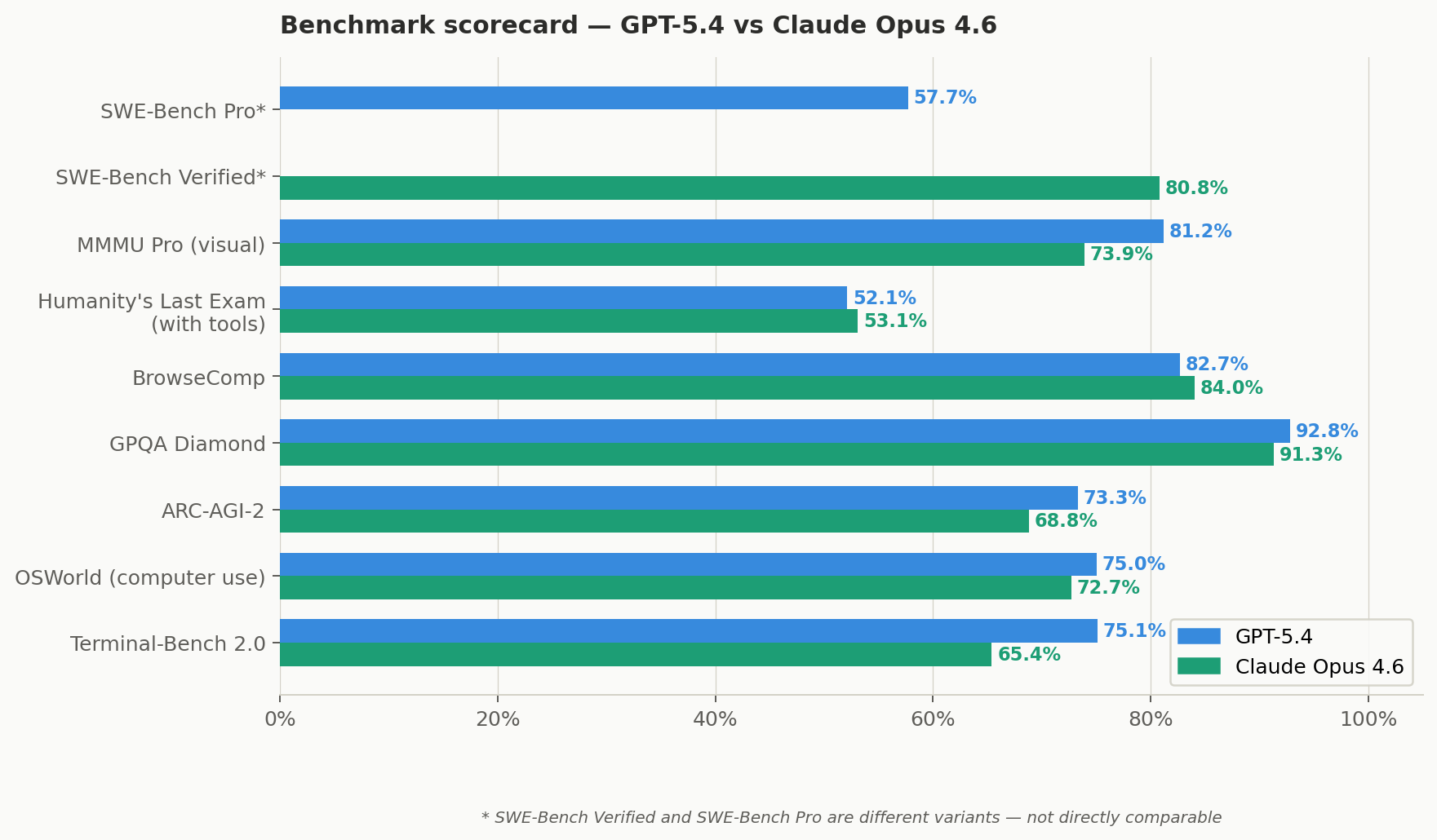
Bars with no value = not reported on that variant. SWE-Bench Verified (Opus: 80.8%) and SWE-Bench Pro (GPT-5.4: 57.7%) are different variants — comparing them directly is not valid.
Full Benchmark Data
| Benchmark | Opus 4.6 | GPT-5.4 | Winner | What it measures |
|---|---|---|---|---|
| SWE-Bench Verified | 80.8% | Not reported | ⚠️ No comparison | Real GitHub issue resolution (standard variant) |
| SWE-Bench Pro | Not reported | 57.7% | ⚠️ No comparison | Harder variant — resists data contamination |
| Terminal-Bench 2.0 ✓ | 65.4% | 75.1% | GPT-5.4 +9.7pt | Git, build systems, CLI debugging |
| BrowseComp ✓ | 84.0% | 82.7% | Opus +1.3pt | Multi-round agentic web search synthesis |
| OSWorld (computer use) | 72.7% | 75.0% | GPT-5.4 | Desktop automation; human baseline = 72.4% |
| ARC-AGI-2 | 68.8% | 73.3% | GPT-5.4 +4.5pt | Novel visual reasoning — resists memorisation |
| GPQA Diamond | 91.3% | 92.8% | GPT-5.4 +1.5pt | Graduate-level scientific reasoning |
| Humanity's Last Exam (no tools) | 40.0% | 39.8% | Tie | Expert multidisciplinary ceiling test |
| Humanity's Last Exam (with tools) | 53.1% | 52.1% | Tie | Same ceiling test with tool access |
| MMMU Pro (visual reasoning) | 73.9% / 77.3%† | 81.2% | GPT-5.4 +4pt | Charts, diagrams, screenshots. † = with tools |
| τ²-bench Telecom (tool calling) | 99.3% | 98.9% | Tie (~) | Domain-specific API tool calling |
| MCP Atlas (multi-tool orchestration) | 59.5% | 67.2% | GPT-5.4 +7.7pt | Coordinating 20+ tools and MCP servers |
| GDPval (knowledge work) | Elo 1606 | 83% vs humans | ⚠️ Incomparable | Different reporting methods — no valid comparison |
| MRCR v2 (1M-token recall) | 76% | — | Opus | Long-context retrieval and coherence |
✓ = directly comparable, confirmed via matching GPT-5.2 Pro baseline scores across both vendors.
Sources: Anthropic release report (Feb 2026), OpenAI release report (Mar 2026), Portkey benchmark cross-reference (Mar 2026).
Win/Loss Summary by Task Category
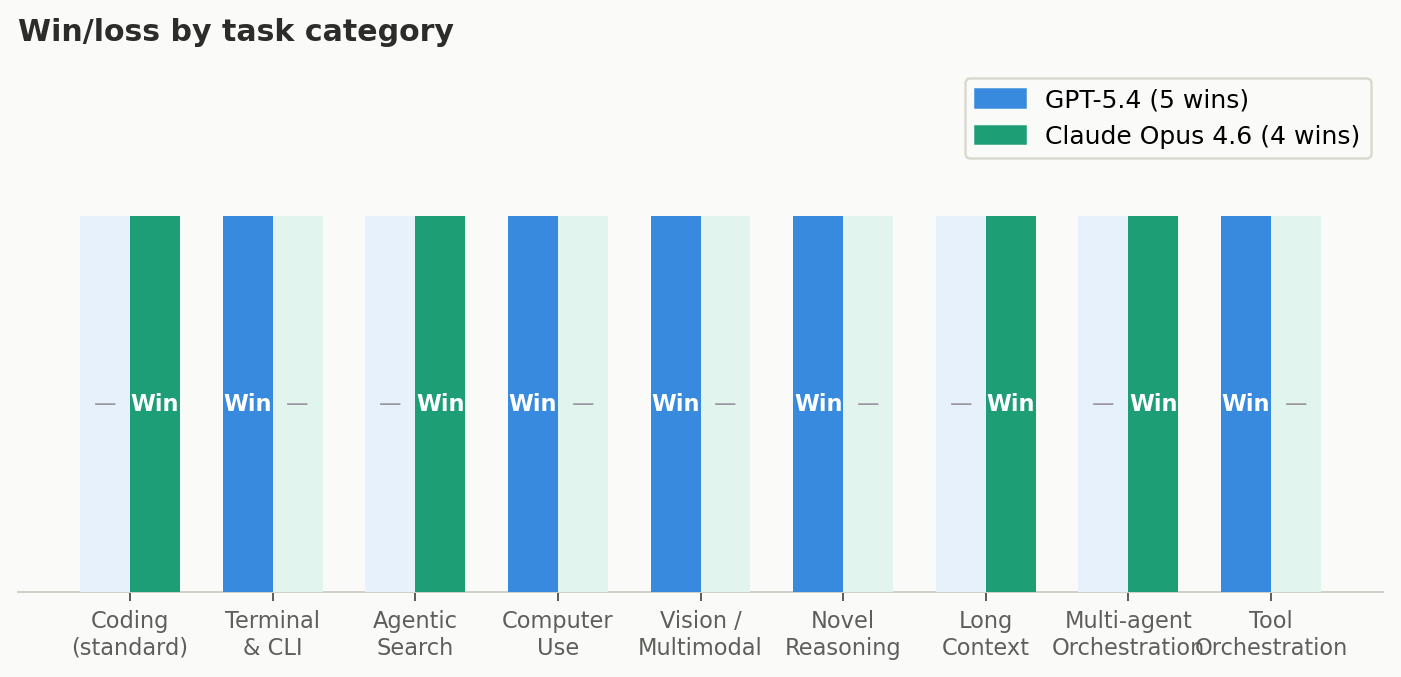
Coding excluded from tally — SWE-Bench Verified and Pro are different variants, not comparable. Final score: GPT-5.4 wins 5 categories, Opus wins 3, 3 ties.
What GPT-5.4 Is Actually Good At
Terminal and CLI work is the clearest advantage. Terminal-Bench 2.0 tests real terminal workflows: file editing, git operations, build systems, debugging CI pipelines. GPT-5.4 scores 75.1% vs Opus's 65.4% — a 9.7-point gap that is consistent across runs. If your agent runs git, debugs build failures, or operates in a shell, GPT-5.4 is the right call.
Computer use crossed the human threshold. GPT-5.4 is the first general-purpose model to exceed human expert performance on OSWorld (75.0% vs the 72.4% human baseline). Opus is strong at 72.7% — also above human — but GPT-5.4's native computer use with no plugins or wrappers required is a meaningful implementation advantage.
Novel reasoning and multi-tool orchestration. GPT-5.4 leads on ARC-AGI-2 (73.3% vs 68.8%) — the benchmark specifically designed to resist memorisation and test genuine fluid intelligence. It also leads on MCP Atlas (67.2% vs 59.5%), which tests coordination across 20+ tools and MCP servers. The Tool Search feature cuts token usage by ~47% in tool-heavy workflows.
Vision and multimodal. If your agent processes charts, screenshots, or diagrams, GPT-5.4 leads MMMU Pro at 81.2% vs 73.9%. Clear advantage, not marginal.
What Claude Opus 4.6 Is Actually Good At
Multi-file architectural refactoring. No clean benchmark captures this, but community evidence is consistent across multiple developer surveys: fewer errors on cross-file type system changes, more stable reasoning chain across files, better handling of implicit dependencies. This is where Opus earns its premium in practice.
Agentic search and synthesis. BrowseComp is one of the few directly comparable benchmarks (confirmed via matching baseline scores). Opus leads: 84.0% vs 82.7%. In multi-round token-heavy search tasks, that accuracy difference reduces retry cost — partially offsetting the higher token price.
Long context past 272K tokens. GPT-5.4's input pricing doubles past 272K tokens — from $2.50/M to $5.00/M, identical to Opus. For full codebase analysis, the cost advantage disappears entirely. Opus's MRCR v2 score of 76% on 1M-token recall confirms the quality holds at those lengths.
Multi-agent orchestration. Agent Teams lets you spawn multiple Opus instances that run in parallel, share task lists, and communicate directly. There is no GPT equivalent. Building coordination infrastructure on OpenAI's stack is possible, but it's code that Anthropic already shipped.
Failure Modes Nobody Documents
Opus 4.6 failure modes
-
Context drift past ~200K tokens. The 1M token context window is real. In practice, on long agentic sessions, you see architectural decisions that contradict earlier ones. The model loses track of decisions made 180K tokens prior. This is an attention distribution problem, not a bug. Long autonomous sessions need explicit state serialisation — not just a long context window.
-
Terminal operations. The 65.4% Terminal-Bench score is not noise. Opus struggles specifically with multi-step terminal sequences that require interpreting ambiguous output — failing test suites with cryptic error messages, build systems with obscure exit codes. This is exactly where GPT-5.4's 9.7-point gap materialises.
-
Cost ceiling before capability ceiling. At $5/$25 per million tokens, you hit budget limits before capability limits on high-throughput pipelines. In practice, most teams route the majority of tasks to Sonnet 4.6 (79.6% SWE-bench, within 1.2 points of Opus at $3/$15) and reserve Opus for genuinely hard cases.
GPT-5.4 failure modes
-
Vague intent handling. When problem statements are ambiguous — which is most of the time in real codebases — GPT-5.4 commits to an interpretation and executes, occasionally in the wrong direction. Opus is meaningfully better at pausing to infer intent before committing. This shows up in multi-file refactoring where the spec has gaps.
-
Multi-agent plumbing. No Agent Teams equivalent. Coordination, parallel execution, shared task lists — you build all of that yourself on OpenAI's stack. It's possible. It's not free.
-
Long-context pricing cliff. Past 272K tokens, GPT-5.4's input cost doubles to $5.00/M — identical to Opus. For large codebase work, the cost advantage disappears and you still get weaker long-context recall scores.
-
Code review quality split. GPT-5.4 catches low-level, hard-to-find bugs (CodeRabbit study: 85% detection across 300 PRs). Opus catches structural and architectural problems. Neither is a complete reviewer alone. In a hybrid pipeline, GPT generates and Opus reviews — you get both.
The Multi-Agent Architecture: When to Combine Them
The pattern that works in production: GPT-5.4 as the execution agent, Opus as the architect and reviewer.
GPT-5.4 generates faster and cheaper. It handles terminal operations, quick iteration cycles, prototyping — output at a fraction of the cost. Then Opus reviews. This is where the cost difference becomes defensible: you're not running Opus on every token, you're running it on the output of a cheaper model to catch what that model missed.
Task classification drives routing:
- Terminal / git / CI / prototype: → GPT-5.4 execution agent
- Complex multi-file refactor / ambiguous spec: → Opus architect agent
- Final review / QA — always: → Opus QA agent, regardless of which agent generated the code
The failure mode to avoid: running both models in parallel on the same task without a decision function. They'll disagree on style, approach, and trade-offs with no arbitration logic. Pick a primary and a reviewer. Not two primaries.
def coding_agent(task: str) -> CodeOutput:
task_type = classify_task(task) # terminal | refactor | review
if task_type in ("terminal", "prototype", "quick_fix"):
draft = gpt54_agent.execute(task)
else:
draft = opus_agent.execute(task) # cross-file, long context
# Always route final review to Opus
reviewed = opus_qa_agent.review(
code=draft,
original_task=task,
review_criteria=["correctness", "architecture", "edge_cases"]
)
if reviewed.has_issues:
return gpt54_agent.fix(reviewed.issues) # cheap iteration
return reviewed.approved_output
Cost at Production Throughput
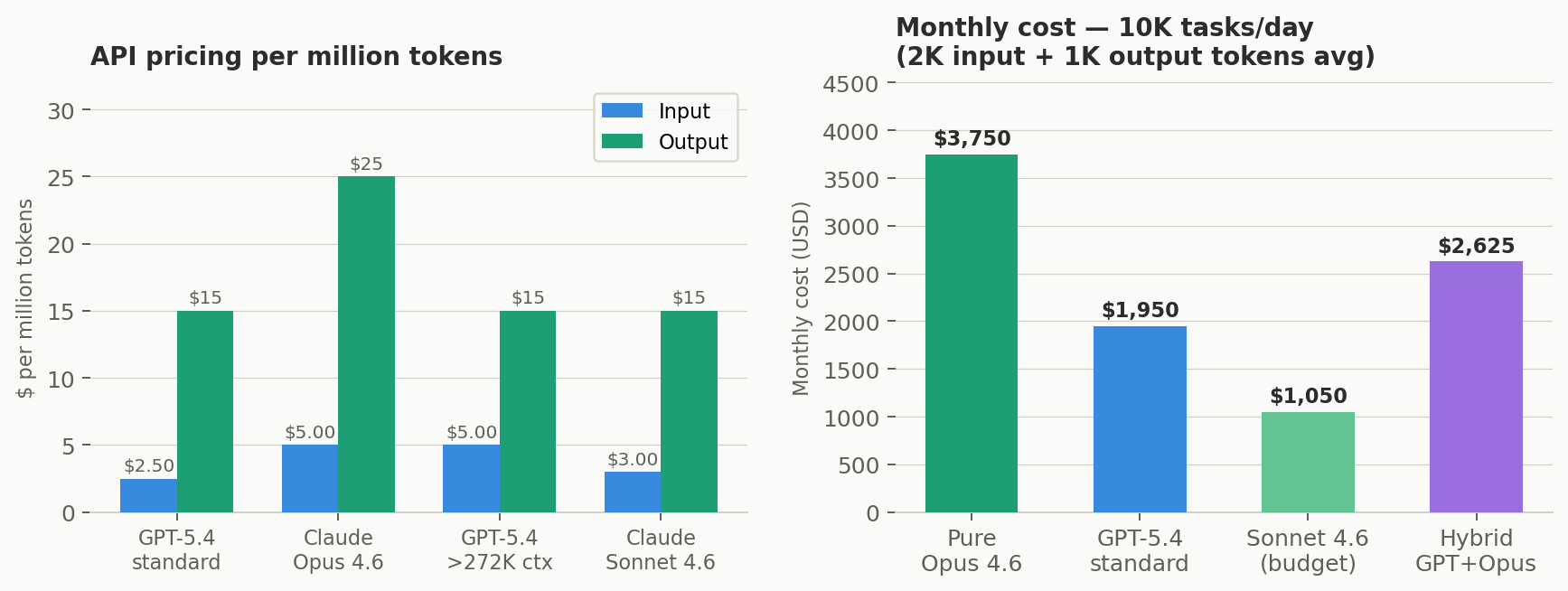
Left: API pricing per million tokens across tiers. Right: monthly cost at 10K tasks/day (2K input + 1K output tokens avg).
| Strategy | Daily cost | Monthly cost | Notes |
|---|---|---|---|
| Pure Opus 4.6 | ~$125 | ~$3,750 | $5/$25 per M tokens. Flat pricing regardless of context length. |
| Pure GPT-5.4 (standard) | ~$65 | ~$1,950 | $2.50/$15 per M tokens. Doubles past 272K input tokens. |
| GPT-5.4 (long context >272K) | ~$115+ | ~$3,450+ | Input doubles to $5/M — Opus cost parity. Quality trails on long-context recall. |
| Sonnet 4.6 (budget tier) | ~$35 | ~$1,050 | 79.6% SWE-bench. Within 1.2pt of Opus. Best cost/quality for most coding tasks. |
| Hybrid: GPT-5.4 execute + Opus review | ~$80–95 | ~$2,400–2,850 | GPT on 80% execution. Opus on complex tasks + all reviews. Best quality-to-cost ratio. |
10K tasks/day at 2K input + 1K output tokens average. GPT-5.4 Tool Search reduces token count ~47% in tool-heavy flows — hybrid cost may be materially lower.
Task Routing Reference
| Task type | Model | Reasoning — with benchmark backing |
|---|---|---|
| Terminal / git / CI debugging | GPT-5.4 | Terminal-Bench: 75.1% vs 65.4% — 9.7pt gap. Consistent across runs. |
| Agentic web search / synthesis | Opus 4.6 | BrowseComp (direct): 84.0% vs 82.7%. Accuracy gap reduces retry cost on multi-round tasks. |
| Desktop / browser automation | GPT-5.4 | OSWorld: 75.0% vs 72.7%. Native computer use. First to exceed human baseline (72.4%). |
| Charts / diagrams / screenshots | GPT-5.4 | MMMU Pro: 81.2% vs 73.9%. Clear visual reasoning advantage. |
| Novel / unfamiliar problems | GPT-5.4 | ARC-AGI-2: 73.3% vs 68.8%. Fluid intelligence, not memorisation. |
| Multi-tool orchestration (20+ MCP) | GPT-5.4 | MCP Atlas: 67.2% vs 59.5%. Tool Search also cuts tokens ~47%. |
| Multi-file architectural refactor | Opus 4.6 | No clean benchmark; consistent community evidence. Fewer cross-file errors. |
| Long context > 272K tokens | Opus 4.6 | GPT-5.4 input price doubles at 272K. MRCR v2: Opus 76%. Flat pricing wins. |
| Graduate-level reasoning | Either | GPQA: 92.8% vs 91.3%. HLE: 40.0% vs 39.8%. Negligible — choose on cost. |
| Domain-specific API tool calls | Either | τ²-bench: 99.3% vs 98.9%. Near-perfect on both. |
| Multi-agent parallel workflows | Opus 4.6 | Agent Teams: no GPT equivalent. Coordination layer is non-trivial to build yourself. |
| High-throughput cost-sensitive | GPT-5.4 | 2× cheaper input, 1.67× cheaper output at standard tier. |
| QA / review in hybrid pipeline | Opus 4.6 | GPT generates (cheap). Opus reviews (catches architectural issues). Best quality-to-cost ratio. |
Capability Matrix
| Capability | Claude Opus 4.6 | GPT-5.4 |
|---|---|---|
| Code readability & comments | Consistently cleaner; better commented; easier to maintain | Structured, competent; follows spec closely |
| Ambiguous intent handling | Pauses to infer intent before committing. Better on vague specs. | Commits to interpretation and executes — occasionally wrong direction |
| Bug detection (PR review) | Stronger on structural / architectural bugs | Strong on low-level bugs; 85% detection in CodeRabbit 300-PR study |
| Multi-file refactoring | Fewer errors; more stable reasoning chain across files | Capable; more errors on cross-file type system changes |
| Rate limits (subscription) | Stricter; heavy Pro users frequently hit ceiling | More generous; Codex Pro users rarely hit ceiling |
| Ecosystem integration | Claude Code, Agent Teams, Anthropic API | GitHub Copilot, Cursor, Codex — zero friction for existing users |
| Tool token efficiency | Standard tool calling | Tool Search: ~47% token reduction in tool-heavy workflows |
The Decision Framework
Use GPT-5.4 when: terminal-heavy operations; rapid prototyping with well-specified tasks; computer use and desktop automation; visual or multimodal input; high-throughput cost-sensitive workloads; already embedded in GitHub Copilot / Cursor / Codex.
Use Opus 4.6 when: multi-file refactoring with complex cross-dependencies; context past 272K tokens (flat pricing wins and quality is better); ambiguous specs where intent must be inferred; multi-agent orchestration via Agent Teams; agentic web search; architectural code review.
Use both when: you need high throughput with high quality — GPT generates, Opus reviews. Budget is real but so are quality requirements.
The one thing to avoid: choosing a model based on the benchmark headline. Six frontier models now score within 1.3 points of each other on SWE-Bench Verified. The real variable is your workflow, your cost structure, and where each model's failure modes land in your specific pipeline.
The technical lead question is not "which model is better." It's "which model fails in a way I can recover from, at my cost structure."
Related Resources: - SWE-bench leaderboard - Anthropic Claude Opus 4.6 release - OpenAI GPT-5.4 release
About the Author
Netanel Eliav builds production AI systems — agentic workflows, RAG pipelines, LLM infrastructure, and evaluation frameworks. He advises engineering teams on agentic architecture and runs projects including Data, Analytics and AI related domains. London-based, global AI leader.