
In today’s data-driven world, where information is king, making accurate predictions is the lifeblood of decision-making. Businesses, healthcare providers, and researchers rely on data models to guide their strategies and actions. However, these models often face a significant hurdle — missing data and features. When real-world data is incomplete, the reliability of predictions becomes compromised, leading to inaccurate insights and potentially costly mistakes. It’s a challenge that has long plagued the field of data analytics.
Project Name: AdaptiveBridge
License: MIT License
Documentation: Click Here
Issue Tracker: GitHub Issues
The Challenge of Missing Data and Features
Imagine you’re tasked with predicting customer behavior for an e-commerce platform. You’ve developed a sophisticated machine learning model, fine-tuned to perfection. But when it comes time to put it into action, the data you receive is far from perfect. Customer profiles are missing key information like age, location, and purchase history. How can your model provide reliable predictions when it lacks crucial data?
This scenario is not unique to e-commerce; it’s a universal challenge across various industries. In healthcare, patient records may lack vital medical history details. In finance, investment predictions may be hindered by incomplete economic data. The list goes on, highlighting the ubiquity of the problem.
The High Stakes of Inaccurate Predictions
The consequences of inaccurate predictions can be severe. In business, a flawed sales forecast can result in overstocked warehouses or lost revenue due to inventory shortages. In healthcare, misdiagnoses stemming from incomplete patient data can have life-altering ramifications. In finance, misguided investment decisions can lead to substantial financial losses. The stakes are high, and the need for reliable predictions is paramount.
The Problem of Inaccurate Predictions
Inaccurate predictions have far-reaching consequences across industries:
- Business: Inaccurate sales forecasts can result in overstocked inventories or missed revenue opportunities. Marketing campaigns may target the wrong audience, wasting resources.
- Healthcare: Misdiagnoses due to incomplete patient data can lead to improper treatments and patient harm. Healthcare providers need reliable predictions to make critical decisions.
- Finance: Investment decisions based on inaccurate economic predictions can result in financial losses for individuals and institutions alike. The financial industry relies on precise forecasts.
- Research: Scientific research depends on accurate predictions for experimentation and data analysis. Incomplete data can undermine research integrity.
Introducing AdaptiveBridge: A Solution for Real-World Data Challenges
AdaptiveBridge, developed by Netanel Eliav, is poised to revolutionize the field of data analytics. It offers a powerful solution to the challenge of missing data and features, enabling organizations to extract value from their data, even when critical pieces are absent. Let’s explore the benefits, issues, and solutions that AdaptiveBridge brings to the table.
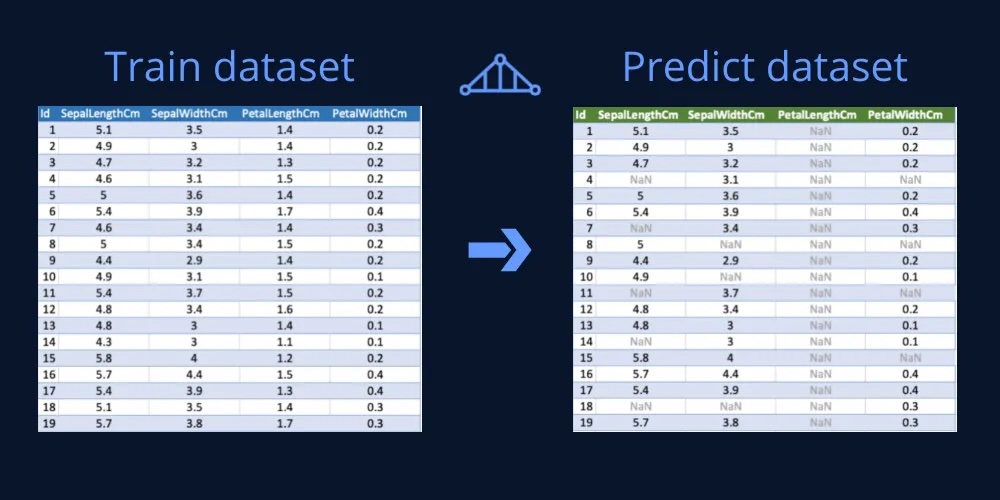
The Benefits of AdaptiveBridge
- Improved Predictions: By intelligently predicting and filling in missing data and even features, AdaptiveBridge significantly improves the accuracy of predictions instead of removing those data points. This leads to more informed decision-making and better outcomes across industries that by definition have data anomalies.
- Seamless Integration: AdaptiveBridge seamlessly integrates with your existing data analytics pipeline. Whether you’re using machine learning models or conducting traditional statistical analysis, AdaptiveBridge can enhance your process without requiring a major overhaul. It can be integrated with the known Python lib Sklearn and supports almost all models.
- Feature Engineering Harmony: AdaptiveBridge isn’t just about filling gaps; it works harmoniously with feature engineering and feature scaling. You can enhance your dataset with engineered features and seamlessly incorporate them into your predictions.
- Customization: AdaptiveBridge offers flexibility with customizable parameters. You can tailor the model to your specific needs, adjusting thresholds and accuracy logic to achieve the desired level of precision. In that way, you can control and balance the training time, accuracy, dependencies, and the ability to close data gaps.
AdaptiveBridge: Bridging the Data Gap
AdaptiveBridge is more than just a tool; it’s a game-changer in the world of data analytics. It empowers organizations to bridge the data gap effectively. With AdaptiveBridge, missing data or features (fully or partially) are no longer insurmountable obstacles. Instead, they become opportunities for more accurate predictions and informed decision-making.
In healthcare, AdaptiveBridge ensures that patient records are complete, enabling accurate diagnoses and treatment plans. In finance, it empowers investment professionals to make data-driven decisions with confidence. In business, it fine-tunes sales forecasts, optimizing inventory management and marketing strategies. In research, it enhances data integrity and accelerates scientific discoveries.
Benchmark Results
Red Wine Quality Dataset
AdaptiveBridge Performance Matrix:
- Non-AdaptiveBridge Model Accuracy: 89.992%
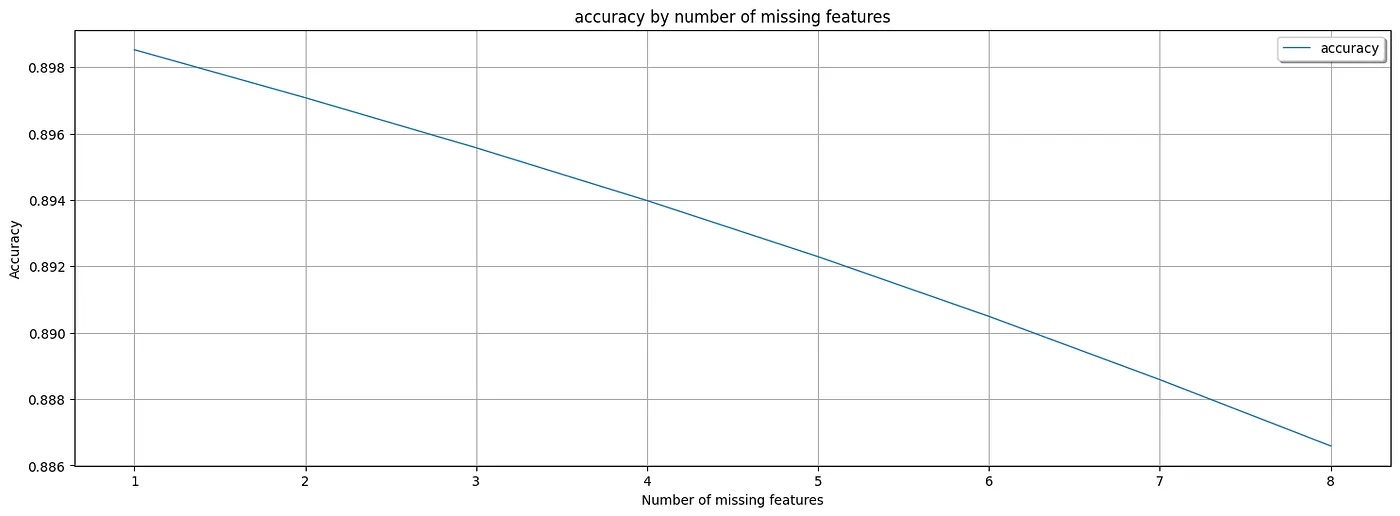
Average Accuracy of AdaptiveBridge for every number of missing features:
- 1 missing feature: **89.852%**
- 2 missing features: **89.707%**
- 3 missing features: **89.557%**
- 4 missing features: **89.398%**
- 5 missing features: **89.229%**
- 6 missing features: **89.049%**
- 7 missing features: **88.858%**
- 8 missing features: **88.658%**
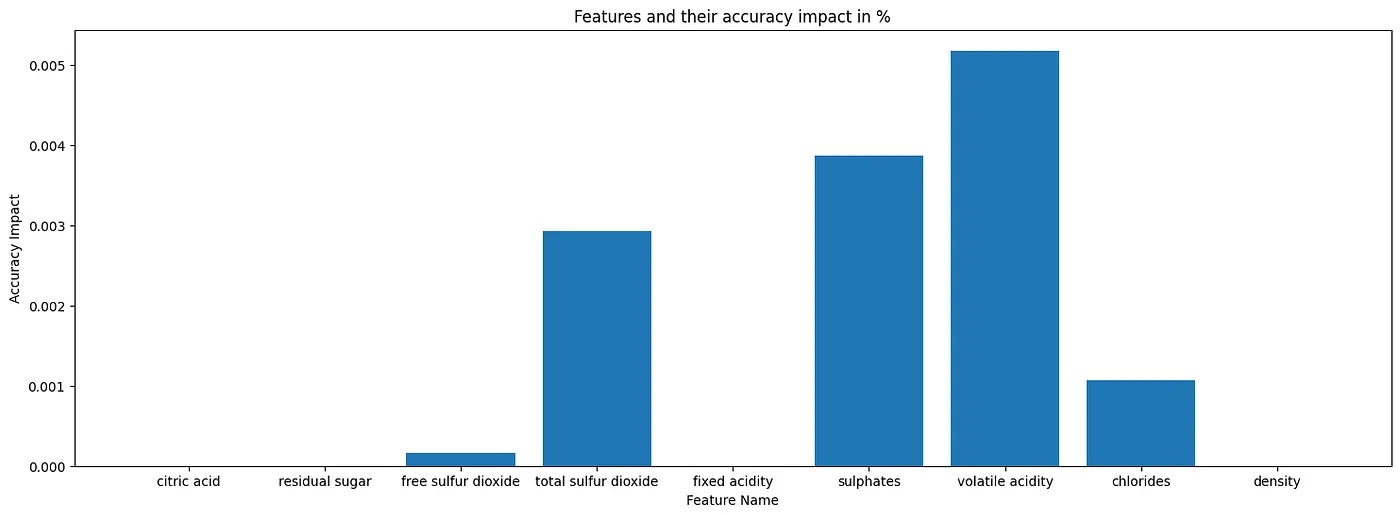
More Benchmark Results for Other Datasets
Boston House Prices Dataset
- Model:
Default LinearRegression() - Number of Features: 12
- Fit Duration: 20.7s
- Avg accuracy with 1 missing feature: 78.37%
- Avg accuracy with 12 missing features: 62.44%
Iris Dataset
- Model:
Default RandomForestRegressor() - Number of Features: 4
- Fit Duration: 0.6s
- Avg accuracy with 1 missing feature: 93.49%
- Avg accuracy with 2 missing features: 92.12%
Red Wine Quality Dataset
- Model:
Default Ridge() - Number of Features: 11
- Fit Duration: 1.1s
- Avg accuracy with 1 missing feature: 89.85%
- Avg accuracy with 8 missing features: 88.66%
White Wine Quality Dataset
- Model:
Default ElasticNet() - Number of Features: 11
- Fit Duration: 5.0s
- Avg accuracy with 1 missing feature: 88.40%
- Avg accuracy with 10 missing features: 88.19%
Breast Cancer Wisconsin Diagnostic Dataset
- Model:
Default RandomForestRegressor() - Number of Features: 30
- Fit Duration: 5.7s
- Avg accuracy with 1 missing feature: 90.03%
- Avg accuracy with 28 missing features: 82.09%
Benchmark Summary
These technical numbers showcase the accuracy performance of AdaptiveBridge across different datasets and scenarios, ranging from regression tasks on housing prices to classification tasks on cancer diagnosis. The benchmarks reveal that even when dealing with a substantial number of missing features, AdaptiveBridge maintains accuracy levels that are highly practical for real-world applications.
Moreover, the benchmark data highlights the versatility of AdaptiveBridge in handling various machine learning models, making it a valuable tool for data scientists and machine learning practitioners working on tasks where data completeness is a challenge. It’s worth noting that these accuracy figures demonstrate AdaptiveBridge’s ability to provide meaningful results despite the inherent data imperfections that often exist in real-world datasets.
Conclusion: The Future of Data Analytics
AdaptiveBridge ushers in a new era of data-driven decision-making. It’s a future where missing features no longer hold back predictions, and data becomes a powerful asset that drives meaningful decisions. Organizations in every industry stand to benefit from the predictive power of AdaptiveBridge.
About the Author
Netanel Eliav builds production AI systems — agentic workflows, RAG pipelines, LLM infrastructure, and evaluation frameworks. He advises engineering teams on agentic architecture and runs projects including Data, Analytics and AI related domains. London-based, global AI leader.