Hold on a moment! Even though ML and Data engineers are on the same team, it’s crucial to remember that the customer (and your budget) simply doesn’t care!
In the realm of data-crunching, where astute minds fashion intricate models, the pursuit of the perfect feature set feels akin to a grand expedition. Envision a dedicated ML engineer, armed with algorithms and propelled by both time and money, embarking on a quest to unveil the enchanting features for their predictive model.
This odyssey into feature engineering excellence can become rather expensive, both in terms of monetary expenditure and temporal investment. ML engineers, resembling modern-day wizards, meticulously fine-tune their models, chasing that elusive combination of features that will unravel the secrets concealed within the data.
But here’s the twist — despite all the diligence and resources poured into constructing an extensive feature set, the resultant model is not a sleek and efficient masterpiece. No, it’s a substantial, unwieldy entity, burdened with superfluous features that barely budge the needle on prediction accuracy.
This isn’t merely a theoretical concern; it adversely impacts the functionality of the model. Large models demand more computational power, voraciously consuming CPU and devouring RAM as if it’s going out of fashion. In today’s world, where RAM constraints underpin scaling issues, this poses a genuine problem.
Project Name: AdaptiveBridge
License: MIT License
Documentation: Click Here
Issue Tracker: GitHub Issues
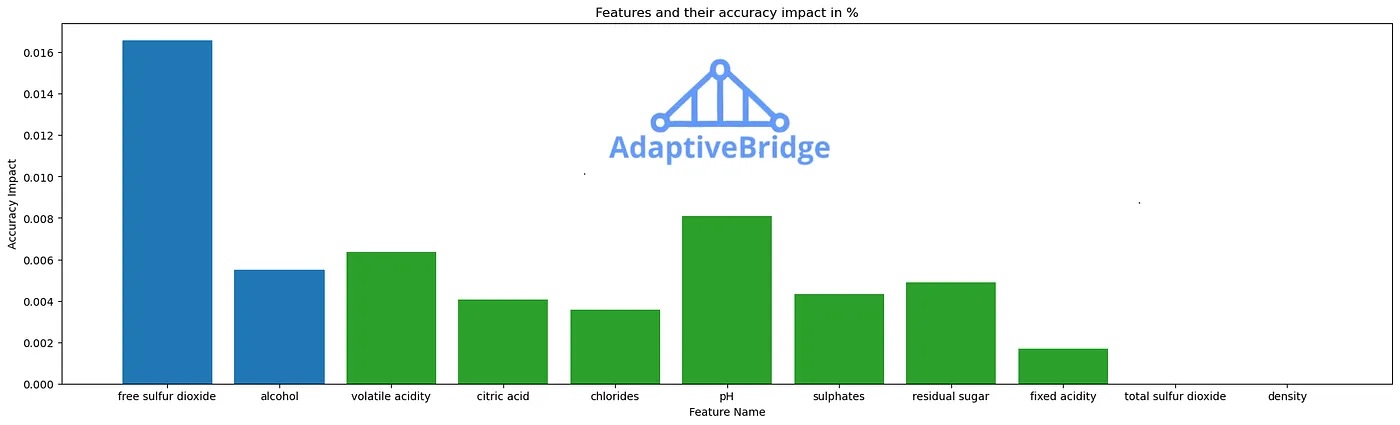
AdaptiveBridge: Feature Importance and Mandatory vs Adaptive
White wine quality prediction: Blue features are mandatory; the rest are nice to have. No need to burden your customers with more than Free Sulfur Dioxide and Alcohol — leverage advanced statistics or AdaptiveBridge for the rest.
AdaptiveBridge, a breath of fresh air in the intricate realm of feature engineering. It daringly challenges the notion that a surplus of features invariably translates to superior predictions. The benchmark results we previously discussed spill the beans — many of those meticulously selected features? Well, as it turns out, they aren’t all that indispensable.
AdaptiveBridge is just an example — the important point is to understand the real-world challenge here.
As our ML engineer navigates the labyrinth of feature importance, AdaptiveBridge unleashes a truth bomb. A multitude of these features contributes minimally to the prediction game, rendering them entirely dispensable. The impact is substantial; the model sheds its excess baggage, evolving into a sleeker, more efficient iteration of itself.
Yet, the narrative doesn’t conclude with the model’s makeover. The handover to data engineers marks a pivotal juncture. A colossal model, brimming with features it truly doesn’t require, could deplete the company’s coffers. The infrastructure and data prerequisites it commands might stretch budgets to their limits and disrupt operational harmony.
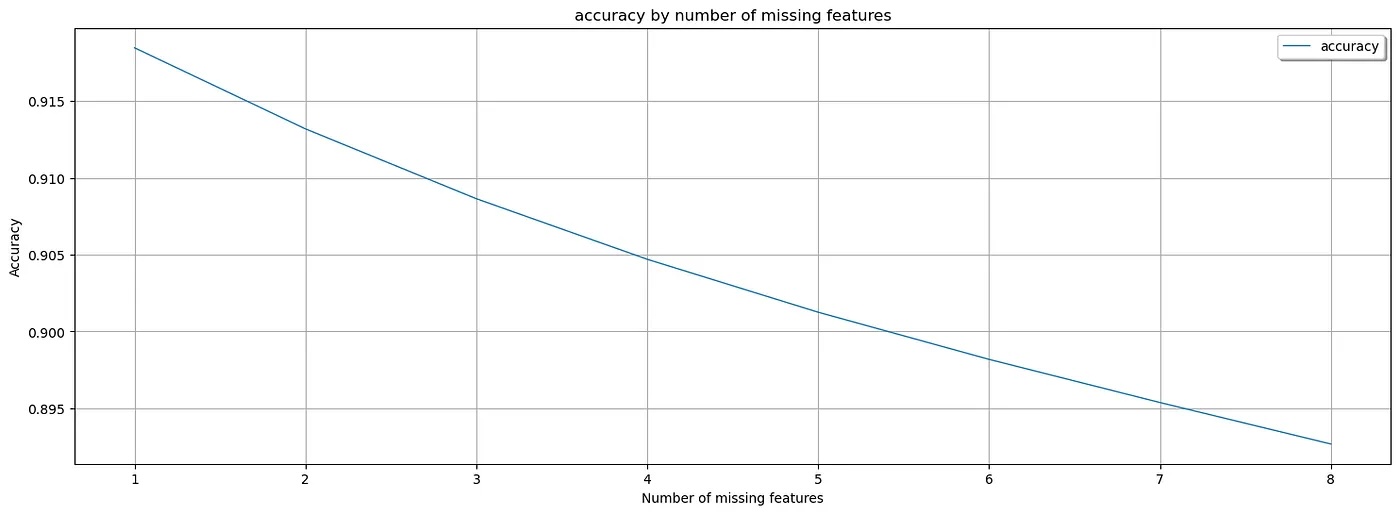
AdaptiveBridge: Performance Matrix
White Wine Quality Prediction: Optimize data requirements without sacrificing accuracy with AdaptiveBridge. AdaptiveBridge Performance Matrix shows the average accuracy for every number of missing features.
Average AdaptiveBridge accuracy with 1 missing features: 91.84%
Average AdaptiveBridge accuracy with 2 missing features: 91.31%
Average AdaptiveBridge accuracy with 3 missing features: 90.86%
Average AdaptiveBridge accuracy with 4 missing features: 90.46%
Average AdaptiveBridge accuracy with 5 missing features: 90.12%
Average AdaptiveBridge accuracy with 6 missing features: 89.81%
Average AdaptiveBridge accuracy with 7 missing features: 89.53%
Average AdaptiveBridge accuracy with 8 missing features: 89.26%
Moreover, customer satisfaction teeters on the edge. If meeting the data requirements becomes a headache, clients might not be overly pleased. In the labyrinth of data crunching, AdaptiveBridge proclaims, “Simplify it!” It demonstrates that a leaner model, honing in on crucial features, not only heightens accuracy but also ensures smooth operations without burning a hole in the pocket.
Consequently, the feature engineering escapade takes a twist with AdaptiveBridge. It overturns the notion that complexity equates to accuracy and signals a future where simplicity reigns supreme. The saga of the ML engineer’s adventurous journey, previously burdened by redundant features, concludes with the revelation that simplicity, infused with a touch of AdaptiveBridge magic, unlocks the true potential of data crunching.